今天在浏览gist的时候,无意中看到了下面这个解析URL的方法,觉得甚是巧妙:
var parser = document.createElement('a');
parser.href = "http://example.com:3000/pathname/?search=test#hash";
parser.protocol; // => "http:"
parser.hostname; // => "example.com"
parser.port; // => "3000"
parser.pathname; // => "/pathname/"
parser.search; // => "?search=test"
parser.hash; // => "#hash"
parser.host; // => "example.com:3000"
巧妙的使用浏览器内置的createElement方法构建一个元素,让浏览器去解析,省去了手动正则匹配。
看看下面的评论:

这是一个天才的出奇简单的方法
 gist需要要一个点赞和分享功能😆
gist需要要一个点赞和分享功能😆
后来在评论中还发现了一个URL的类,他直接支持解析链接,发现这个虽然更好,但是支持浏览器不够全面,可以看到又是我们的IE,那么特例独行,格格不入。这又让我想起微软程序员公开演讲的时候,使用Edge浏览器,不争气Edge崩溃了,不得不当场换chrome继续演讲,真是尴尬啊。
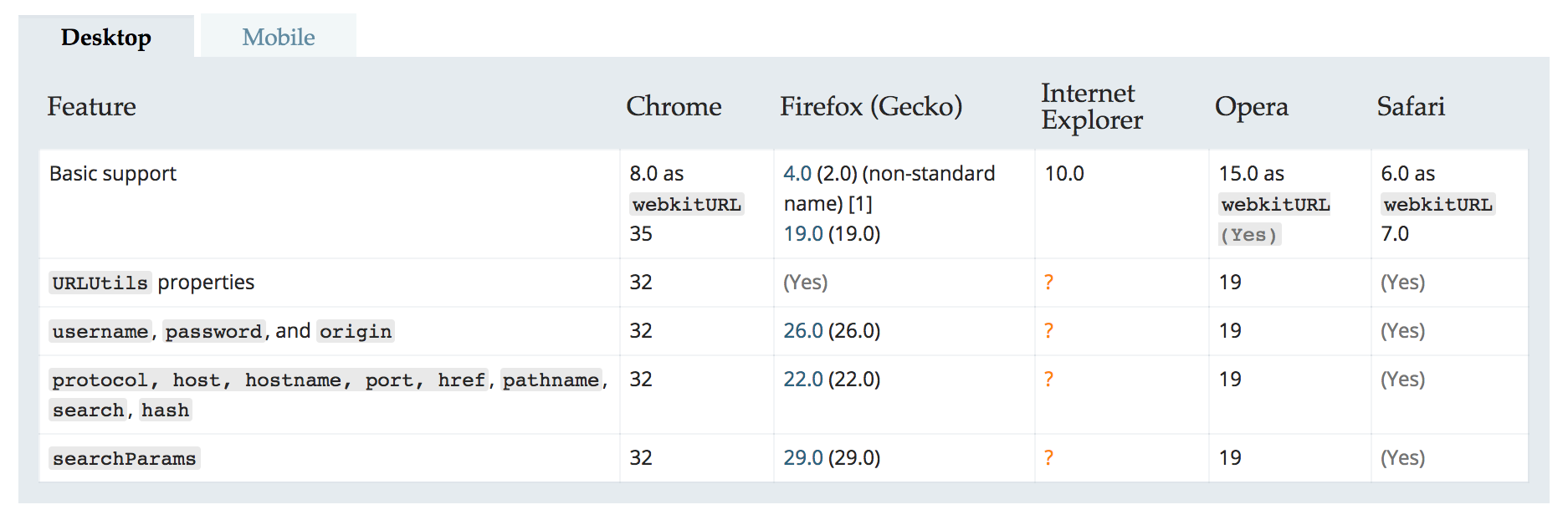
所以,可以将两种方法结合起来使用,优先使用URL类,不支持的时候再使用createElement
/**
* 解析URL
* @param {string} url 要解析的链接地址
* @return {object} 包含解析之后的url信息
*/
function parser(url)
{
var parser;
try {
if (typeof URL === "function") {
parser = new URL(url);
} else {
parser = document.createElement('a');
parser.href = url;
}
} catch (err) {
throw new Error("not a vaild url!");
}
return parser;
}
这个还有一个不太方便的就是获取参数,我来给他完善下获取参数的功能,应该将两个函数结合起来,但没想到好的方法,感觉继承好像搞不定,就先这么放着,想到方法了,把继承这里深层了解了在完善:
/**
* 获取url中的参数
* @param {object} 解析后的url
* @return {object} 要获取的参数值,默认为空
*/
function getParams(parser, name)
{
var search = parser.search.substr(1),
items = search.split("&");
if ("undefined" === typeof(name)) {
var ret = {};
items.forEach(function(p){
var kv = p.split("=");
ret[kv[0]] = kv[1];
});
return ret;
} else {
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = search.match(reg);
if(r!=null) {
return decodeURI(r[2]);
} else {
return null;
}
}
}
看看下面的例子
var urlInfo = parser("http://example.com:3000/pathname/?who=you&name=&yrt&search=test#hash");
console.log(urlInfo.host); // output example.com:3000
console.log(getParams(urlInfo)); //output {who: "you", name: "", yrt: undefined, search: "test"}
console.log(getParams(urlInfo, "yrt")); // output null